Berkely AI Research
 In het Berkeley AI Research center krijgen we een presentatie van Professor Pieter Abbeel, burgerlijk ingenieur, alumnus van de KUL, PhD van Stanford en sinds 2008 professor in Berkeley.
In het Berkeley AI Research center krijgen we een presentatie van Professor Pieter Abbeel, burgerlijk ingenieur, alumnus van de KUL, PhD van Stanford en sinds 2008 professor in Berkeley.
Twee uur opperste concentratie om te kunnen volgen waar deze man en met hem de scherpste geesten van Silicon Valley mee bezig zijn.
Previously unseen towels
Robots zijn al een tijdje op de markt maar blijven behoorlijk duur. Er is (nog) geen Moore’s law voor robotic hardware. De prijs gaat eerder lineair dan exponentieel naar beneden. In 2007, wanneer Pieter zijn onderzoek start, is het programmeren van robots heel tijdsintensief en dus duur. Pieter besluit zich hierop te concentreren. De hardware van robots is behoorlijk ok maar hoe kan de software revolutionair verbeterd worden.
Pieter start met het robotiseren van een schijnbaar eenvoudig proces: autonomously folding a pile of 5 previously-unseen towels: een proces met verschillende, niet repetitieve sequenties, volgend op een oneindig variërend uitgangspunt. Pieter en zijn team slagen er in om de robot zover te krijgen dat hij autonoom eender welke berg handdoeken kan plooien. Op zich een straf resultaat maar het kost het team 2 jaar om de programmeerklus te klaren en de robot werkt heel traag. Het filmpje hieronder toont het resultaat. Het duurt 20 minuten om één handdoek op te pakken. Economisch totaal irrelevant dus.
Deze catch, wordt het uitgangspunt van Pieters verdere onderzoek:
Robots, stap voor stap, sequentieel programmeren voor opeenvolgende taken (grab, sort, stretch, fold, pile …) is heel complex en veel te tijdrovend. De if this …, then that … sequenties die geprogrammeerd moeten worden zijn heel complex voor behoorlijk eenvoudige handelingen.
In plaats van dit proces verder te perfectioneren draait het team van Pieter de vraagstelling volledig om:
“Wat gebeurt er als we software schrijven die niet meer focust op de specifieke opgelegde taken maar op het beslissingsproces van de robot zelf?”
De oplossing focust zich op het leerproces eerder dan op de uit te voeren taken. Het voordeel van dergelijke software is dat ze gebruikt kan worden om eender welk proces aan te leren. Machine learning dus.
Digital Object Recognition
De doorbraak van Machine Learning kwam er bij het ontwikkelen van zoekrobots voor beelden (bv. Google images). Hoe herken je dat een bepaalde verzameling pixels (een digitale foto) de afbeelding van bv. een kat bevat?
Ook hier heeft men het algoritme volledig moeten herdefiniëren. Van het één voor één herkennen van verschillende kenmerken van een kat (twee oren, een kleine neus, snorharen, klein, …) tot het beantwoorden van de eenvoudige vraag: “Is dit een kat?”
De oplossing lag hem in het gebruik van de kracht van het internet zelf. In de macht van de grote getallen. “Als we duizenden kattenfoto’s indexeren als een kat, dan kan de software de volgende foto misschien zelf herkennen…
Ook hier wordt eigenlijk het leerproces van de mens geïmiteerd. Voor een kind weet wat een kat is heeft het eerst duizenden keer in het boekje met dieren gekeken.
Maar hoe herkent het algoritme die 1001ste foto dan? De oplossing lag ook hier bij de mens, bij de natuur. Het menselijk oog bestaat uit miljoenen zintuigcellen die elk een stukje van het beeld waarnemen. Die miljoenen beeldjes worden door de hersenen tot één beeld samengesteld dat op zijn beurt vergeleken wordt met de in ons geheugen aanwezige referentiebeelden.
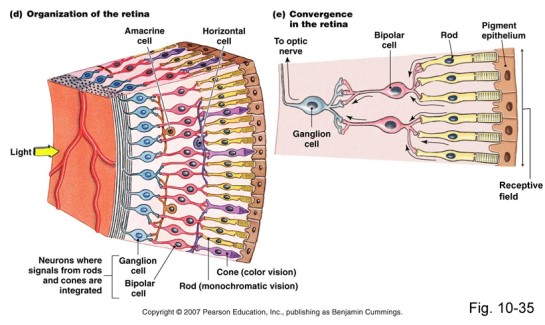
Kan zoiets in software geïmiteerd worden? Kunnen we, dat door de evolutie gemodelleerde proces, digitaal repliceren? Zo’n manier van denken heet biomimicry en zorgde in computer science al vaak voor doorbraken.
De oplossing lag, zoals vaak, in verhoogde rekenkracht (Moore’s law) en in het gebruik van Convolutional Neural Networks (CNN).
Als we 1) de informatie uit een beeld (van bv. een digitale camera) kunnen reduceren tot verschillende kleinere elementen die we 2) op hun beurt exact kunnen matchen met diezelfde kleine elementen uit het referentiemateriaal dan dan kan 3) het originele beeld gematcht worden met het referentiemateriaal.
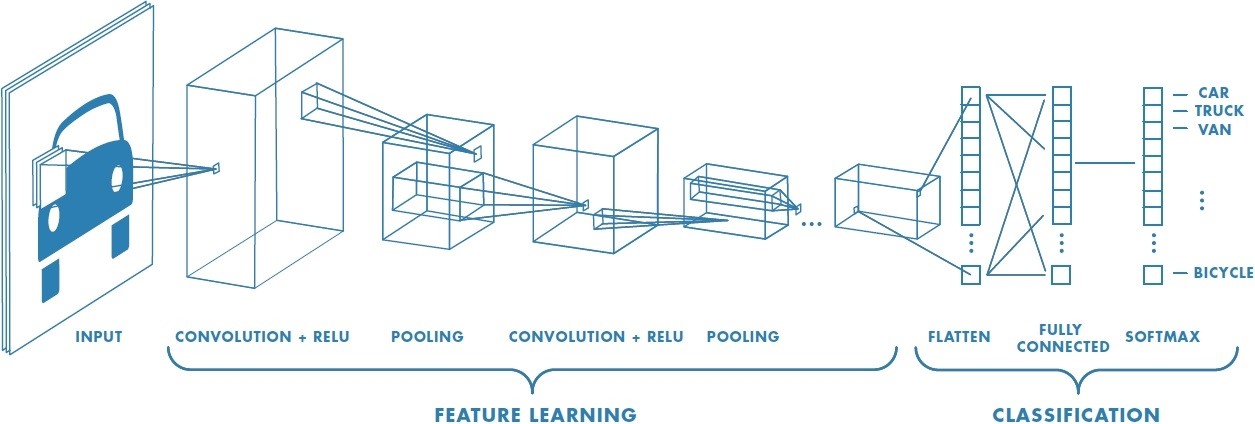
1. Deep Supervised Learning
Om dit proces digitaal te kunnen uitvoeren moeten miljoenen convoluties (wiskundige functies) uitgevoerd worden en er moeten miljoenen referenties beschikbaar zijn. Maar vanaf 2012 was de rekenkracht beschikbaar en het internet stond intussen vol met kattenfoto’s. De resultaten waren verbluffend. Hoe meer referentiemateriaal werd toegevoegd en geïndexeerd, hoe beter het algoritme werkte.
Dat leerproces werd Deep Supervised Learning genoemd.
In 2009 startte Princeton University de ImageNet Challenge, een competitie voor de beste Image Detection. Vanaf 2012 gebruikten de deelnemers Supervised Learning via Convolutional Neural Networks, de error rate zakte spectaculair.
In 2015 werd het niveau van de mens gehaald. Vandaag benadert men de perfectie en is de competitie opgedoekt.
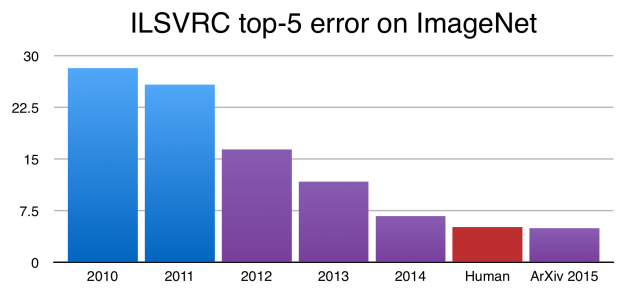
Naast image recognition is er ondertussen ook speech recognition en video recognition, allemaal gebaseerd op dezelfde CNN principes.
Opgelet! Om dergelijk Deep Supervised Learning te realiseren moeten miljoenen referenties handmatig geïndexeerd worden. De supervisor moet daar heel veel mankracht/budget aan spenderen en moet over gigantische hoeveelheden gestructureerde data beschikken. Spek voor de bek van de grote techspelers dus…
De honderden met camera’s uitgeruste wagens die vandaag, supervised, door San Francisco rijden maken deel uit van nog zo’n Supervised Learning project. Ze verzamelen referentiedata voor de neural networks van de self-driving cars die straks door onze straten zullen rijden.
2. Goal Oriented Learning
Ondertussen waren de onderzoekers al bezig aan de volgende uitdaging.
- Hoe kunnen we het werk van dat manueel indexeren uitschakelen?
- Kunnen we de robots zelf laten beslissen of een bepaalde actie goed of slecht is?
- Wat indien we de computer een doel geven waardoor hij/zij die beslissing zelf kan nemen?
Het Goal Oriented Learning was een feit.

In plaats van een robot in een hindernissen parcours te leren om obstakels te omzeilen, werd hem/haar gevraagd om zo ver mogelijk in een bepaalde richting te lopen. Elke actie die niet het gewenste resultaat oplevert werd geëlimineerd, terwijl verder geïtereerd werd met acties die een resultaat in de goede richting opleverden.
De resultaten worden weergegeven in het onderstaande filmpje en zijn opnieuw verbluffend.
Fascinerend is dat dit algoritme los staat van wie/wat het gebruikt. Het kan evengoed gebruikt worden voor een figuur op 2, 4 of 6 poten. De resultaten zijn gelijk. Het algoritme leert door trial en error omgaan met de opgelegde beperkingen.
De gelijkenissen met een lerend levend wezen zijn bijna griezelig.
Er blijven uiteraard nog problemen over. Hoe zorg je voor stabiliteit in dergelijk proces? Hoe zorg je voor credit assignment in complexere omgevingen? Hoe zorg je ervoor dat het systeem steeds verder exploreert en zich niet nestelt in suboptima.
Abbeel zal het zeker nog oplossen…
3. Unsupervised learning
Bij supervised learning moeten eerst referenties geclassificeerd worden alvorens nieuw materiaal gecatalogiseerd kan worden. Zou het mogelijk zijn dat de computer zelf referentie materiaal genereert en dat zelf aangemaakte materiaal ook zelf kan catalogiseren?
Ja hoor. Als een computer tegen zichzelf kan spelen dan kan hij die ervaringen ook gebruiken als bijkomend referentiemateriaal voor zijn/haar neurale netwerk en zo steeds slimmer worden. Het is met deze techniek van Unsupervised learning dat Google AI wereldkampioen geworden is in het moeilijkste spel dat de mens ooit heeft bedacht.
Abbeel paste deze technieken toe om zijn robot Brett blokjes in een doos te leren stoppen.
“This is Brett, he does Deep Learning. If you want to meet him, he lives on the 7th floor…”
Brett genereert zelf probeerscenario’s, evalueert zelf of ze succesvol zijn of niet en werkt daar dan op verder. Het filmpje bekijken is bijna ontroerend.
En het kan nog gekker. Wat indien we het catalogiseren van beelden omdraaien? En niet langer van beeld naar tekst gaan maar van tekst naar beeld? En dus beelden laten genereren op basis van een beschrijving zoals bv: “a little bird with a red chest and a white collar”? En die beelden gaan vergelijken met geïndexeerd referentiemateriaal? En zo de gegenereerde beelden steeds verder verfijnen?
Exactly, dan kunnen we automatisch beelden genereren die niet eens bestaan. Beelden van vogels die lijken op echte vogels maar fake zijn. Echt fake nieuws met echte fake beelden wordt dan (trieste) realiteit…
Abbeel is zich bewust dat hij zich op een terrein bevindt waar niemand zich ooit eerder begaf.
Hij bevindt zich momenteel in het selecte clubje van mensen die de mogelijkheden van AI ten gronde begrijpen. Geen wonder dat Elon Musk hem selecteerde voor zijn denktank OpenAI.
Ik hoop dat die gasten voldoende hun leerling tovernaarschap beseffen. Ze zijn er alleszins slim genoeg voor.
Twee uur kost het Pieter Abbeel om dit verhaal te vertellen: helder, meeslepend, op zijn gemak. Wat een voorrecht om deze man te mogen spreken!